issues.app (5): Database design
Defining the logical organization of an issue tracker’s data.
Most useful applications need to manage data. Generally, the more complex the application, the harder it becomes to efficiently organize this data. As it turns out, there is a lot to think about when it comes to managing the kind of data you might find in an issue tracker. This writeup describes the initial database schemata that will support issues.app, including the thought processes that led to several important design decisions.
Table of Contents
The database schema
The easiest way to start the design process (at least for me) is to define the conceptual things that the application will need to manage. If we’re talking about an issue tracker, I say we will need:
- issues, no surprises there,
- projects, to organize issues into different areas of work,
- users, to work on the issues,
- user roles, to specify which operations (e.g., updating an issue, archiving a project) can be performed by each user,
- comments and messages, to allow public and private communication within the app.
Each of these things gets a table in the database. All tables have an ID column, which serves as the primary key for each table. As described in the previous writeup, each table will be implemented as a Python class that inherits from SQLAlchemy’s Model class. The relationship between different tables is shown in the diagram below.
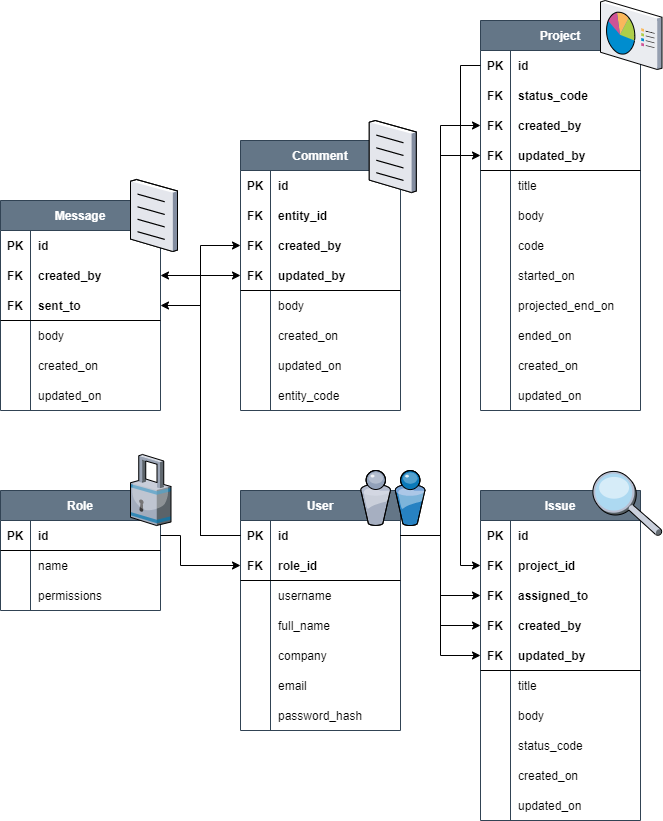
Let’s talk more about some of the features of this design.
Messages and comments
There are two kinds of communication available in the app: (1) private messaging, in which a comment is sent by one person to another, and (2) public comments, which are posted on an issue or project. Since comments can be associated with more than one conceptual object (or what I’m calling an entity), the Comment table is a bit more complex than the Message table.
For that reason, the Comment table keeps track of two things:
- the entity ID, holding the unique identification number of the entity,
- the entity code, which identifies what kind of entity is being commented on.
The entity codes are stored in the Python dictionary subclass shown below. The name() method allows an instance of the class to perform code-to-name lookups.
src/models.py » Entity
class Entity(dict):
def __init__(self):
self['ISSUE'] = 1
self['PROJECT'] = 2
self['FORUM'] = 3
def __getattr__(self, attr):
return self.get(attr)
def name(self, code):
for key, val in self.items():
if val == code:
return key
# complain if code is absent
raise KeyError('input is not a valid entity code')
Status codes
The status of an issue will be stored as an integer (Issue.status_code), which can take one of several values. In the end I settled on the states shown in the flowchart below (Fig. 2), with arrows indicating the possible transitions between states.
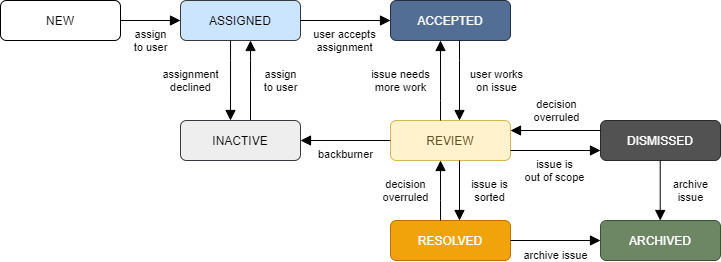
The usual setting I have in mind for this app involves employees who work on issues, reviewers, who check the employees' work, and managers, who have the final say. In a hypothetical situation, their interactions with the application might look like this:
- A new issue is created on behalf of a client.
- The manager assigns the issue to the employee (NEW → ASSIGNED).
- The employee accepts the assignment (ASSIGNED → ACCEPTED).
- After completing work to resolve the issue, the employee indicates that the issue is ready for some QA (ACCEPTED → REVIEW).
- The reviewer realizes that an issue is up for review, goes over the work of the employee, and decides that the issue has been resolved (REVIEW → RESOLVED).
- Noticing that an issue has been resolved, the manager verifies that the work has indeed solved the problem and archives the issue (RESOLVED → ARCHIVED).
A Python dictionary subclass will be used to hold the status data and perform code-to-name lookups. Four of these status values (NEW, ACTIVE, INACTIVE, ARCHIVED) will likely be used for projects, using Project.status_code.
src/models.py » Status
class Status(dict):
def __init__(self):
self['NEW'] = 1
self['ASSIGNED'] = 2
self['ACCEPTED'] = 3
self['REVIEW'] = 4
self['RESOLVED'] = 5
self['DISMISSED'] = 6
self['ACTIVE'] = 7
self['INACTIVE'] = 8
self['ARCHIVED'] = 9
def __getattr__(self, attr):
return self.get(attr)
def name(self, code):
for key, val in self.items():
if val == code:
return key
# complain if code is absent
raise KeyError('input is not a valid status code')
Roles and permissions
A user will be able to perform different operations in the application, depending on what role they have in the company. Managers, for example, will generally have more permissions than regular employees, who in turn will have more permissions than associates (non-employees or temporary workers). The table below shows what this privilege hierarchy looks like.
| clients | associates | employees | reviewers | managers | |
|---|---|---|---|---|---|
| 💬 message users | ✅ | ✅ | ✅ | ✅ | ✅ |
| ✍️ create comments | ✅ | ✅ | ✅ | ✅ | |
| 🎫 create issues | ✅ | ✅ | ✅ | ||
| 📋 review issues | ✅ | ✅ | |||
| 📁 create projects | ✅ | ||||
| 🗃️ resolve and archive | ✅ |
Depending on what role each user plays in the company, they will be able to perform different operations. The different permissions are stored in the dictionary subclass shown below.
src/models.py » Permission
class Permission(dict):
def __init__(self):
self['NOTHING'] = 0
self['MESSAGE_USERS'] = 1
self['CREATE_COMMENTS'] = 2
self['CREATE_ISSUES'] = 4
self['CREATE_PROJECTS'] = 8
self['RESOLVE_ISSUES'] = 16
self['ARCHIVE_PROJECTS'] = 32
self['EVERYTHING'] = 64
def __getattr__(self, attr):
return self.get(attr)
def name(self, code):
for key, val in self.items():
if val == code:
return key
# complain if code is absent
raise KeyError('input is not a valid permission code')
Note that the numeric values of these permissions are powers of two, which allows for permissions to be combined and easily decoded by the webapp. That means we can, for instance, define the role of an employee by the sum of three privileges:
r = Role(name='employee', permissions=p.MESSAGE_USERS + p.CREATE_COMMENTS + p.CREATE_ISSUES)
MESSAGE_USERS, making their effective privileges equal to CREATE_COMMENTS.
Addendum
As it turns out, there’s a much better data structure that can be used instead of these custom dictionary subclasses I cooked up. Ladies and gentlemen, let me present: the humble enum.
By subclassing an enum, we not only gain access to some handy features, but we also get away with using far less code. For example, let’s rewrite the Permission class like this:
class Permission(IntEnum):
NOTHING = 0
MESSAGE_USERS = 1
CREATE_COMMENTS = 2
CREATE_ISSUES = 4
CREATE_PROJECTS = 8
RESOLVE_ISSUES = 16
ARCHIVE_PROJECTS = 32
EVERYTHING = 64
Here’s a quick demonstration of what this class can do for us:
Permission.CREATE_ISSUES→<Permission.CREATE_ISSUES: 4>Permission.CREATE_ISSUES.name→'CREATE_ISSUES'Permission.CREATE_ISSUES.value→4Permission(4)→<Permission.CREATE_ISSUES: 4>Permission(5)→ValueError: 5 is not a valid PermissionPermission.CREATE_ERROR→AttributeError: CREATE_ERROR
Safety and convenience, all in one package. Beautiful, isn’t it?
Summary
This is a first attempt to define the logical organization of data in the issue tracker. Definitely a work in progress, but it should be enough to get the app off the ground and moving towards a working prototype.
Looks like I can’t put off working on the user interface for much longer!